Multilayer Perceptron
Early in the section for perceptron, we saw it as being an algorithm (or as can be said, an analog machine) that is basically a linear classifier. Now, in the MLP, the layer in itself is a linear function, but from one layer to another, nonlinearity can be introduced by use of activation functions.
So what are activation functions? - they are just mathematical functions that are introduced at the end of units to introduce non-linear complexities to the model. sgn is not non-linear because it is not-differentiable, hence why we couldn't have computed the gradients the Pytorch way while implementing the perceptron.
So what are activation functions? - they are just mathematical functions that are introduced at the end of units to introduce non-linear complexities to the model. sgn is not non-linear because it is not-differentiable, hence why we couldn't have computed the gradients the Pytorch way while implementing the perceptron.
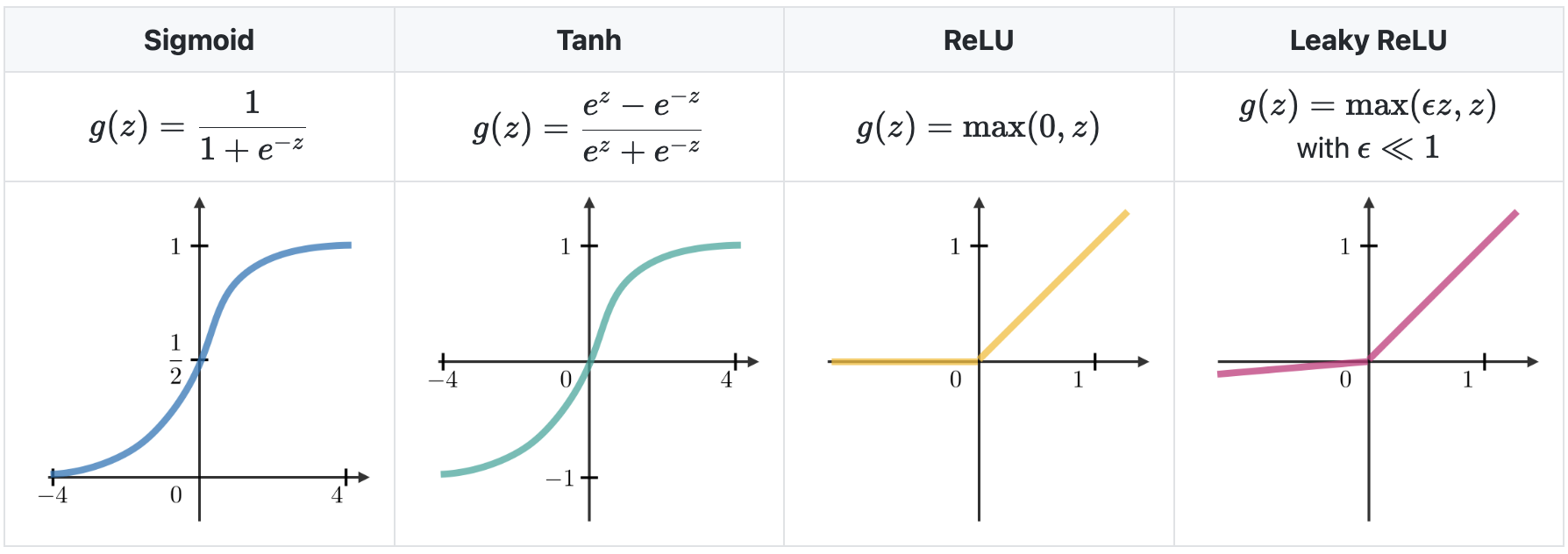
courtesy of Stanford deep learning cheatsheet
Demystifying MLP
So how does a single layer perceptron look like? Let's understand this programmatically by creating one composed of 4 perceptrons.
The approach to implementing this is by first using naive for loop to stack each perceptron side by side then it is efficiently implemented using a matrix block that specifies the weights and the biases.
But first, let's create a Linear layer, PyTorch's implementation of perceptrons stacked side by side, or as the cheat sheet above visualizess it, one perceptron on top of another the 4 blue nodes on top each other.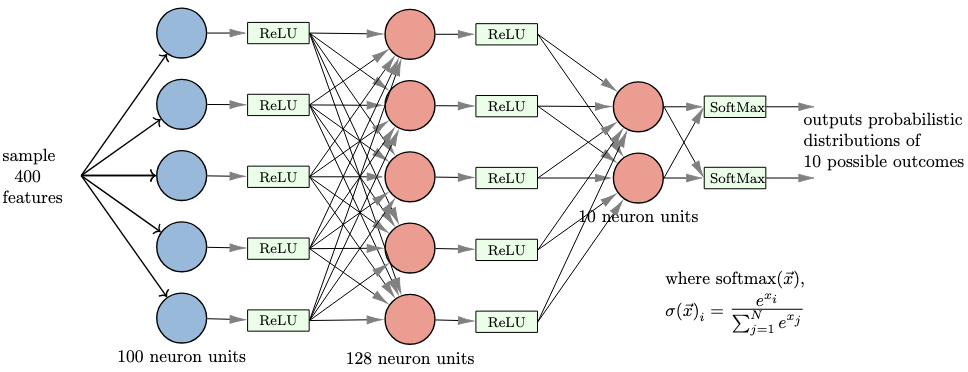
The approach to implementing this is by first using naive for loop to stack each perceptron side by side then it is efficiently implemented using a matrix block that specifies the weights and the biases.
But first, let's create a Linear layer, PyTorch's implementation of perceptrons stacked side by side, or as the cheat sheet above visualizess it, one perceptron on top of another the 4 blue nodes on top each other.
tensor([[ 0.6222, 0.1250, -0.6566, 0.5412],
[ 0.2936, 0.7253, -0.9345, 0.4647],
[-0.5043, 0.5410, -0.5203, -0.3301]], grad_fn=<AddmmBackward0>)
Let's start with the perceptron, but without the activation function (without the sgn function used in the previous section or a differentiable function like tanh) since PyTorch's version doesn't have an activation function within.
Now onto stacking n number of perceptrons side by side, the exact number to be specified during instantiation.
Knowing that the input is passed to each node, then the perceptron computes the result, let's implement the __call__ magic method to do this.
Note: the formatting done above is just to reduce floating point precision to 4 dp to reduce verbosity.
Now, initializing my single-layer, 4 perceptrons stacked side by side. Or any number of perceptrons you wish to have.
Now, initializing my single-layer, 4 perceptrons stacked side by side. Or any number of perceptrons you wish to have.
4 perceptrons ==> shape torch.Size([7])
[0.7342, -0.838, 6.8438, 2.8546]
[-0.2729, 3.1664, 3.7544, 0.3837]
[-2.8693, 3.1136, 2.5533, 0.2767]
Now let's do something interesting, let's transfer weights from PyTorch's Linear layer to the naive implementation. If the two are the same architecture, then the output should actually be the same.
Computing the outputs
[0.6222, 0.125, -0.6566, 0.5412]
[0.2936, 0.7253, -0.9345, 0.4647]
[-0.5043, 0.541, -0.5203, -0.3301]
#
###########################
## same result, nice!!!
###########################
Now let's actually utilize the compactness of matrices to implement an efficient version of the 4 perceptrons stacked side by side (what I call the single layer perceptron).
Again, copying weights and biases from the Linear layer!
tensor([[ 0.6222, 0.1250, -0.6566, 0.5412]], grad_fn=<AddBackward0>)
tensor([[ 0.2936, 0.7253, -0.9345, 0.4647]], grad_fn=<AddBackward0>)
tensor([[-0.5043, 0.5410, -0.5203, -0.3301]], grad_fn=<AddBackward0>)
OR
tensor([[ 0.6222, 0.1250, -0.6566, 0.5412],
[ 0.2936, 0.7253, -0.9345, 0.4647],
[-0.5043, 0.5410, -0.5203, -0.3301]], grad_fn=<AddBackward0>)
#
###########################
## again same result!!!
###########################
The class created above, can be rewritten as a base PyTorch class using the torch.nn.Module, the base class for PyTorch models, as seen below
All this was for the understanding of Linear layer, for which the in-built PyTorch module described at the beginning is recommended for use.
Multiple layers of the perceptrons stacked side by side is what is now known as "Multilayer Perceptron", and is as below in code implementation
Multiple layers of the perceptrons stacked side by side is what is now known as "Multilayer Perceptron", and is as below in code implementation
tensor([[0.1164, 0.0934, 0.1123, 0.1057, 0.0991, 0.0944, 0.0966, 0.0794, 0.1028,
0.0999]], grad_fn=<SoftmaxBackward0>)