Once upon an apple...
at a time when Isaac Newton lived

There existed the calculus ofgradients, a fancy word to say derivatives, or the rate of change of a function.
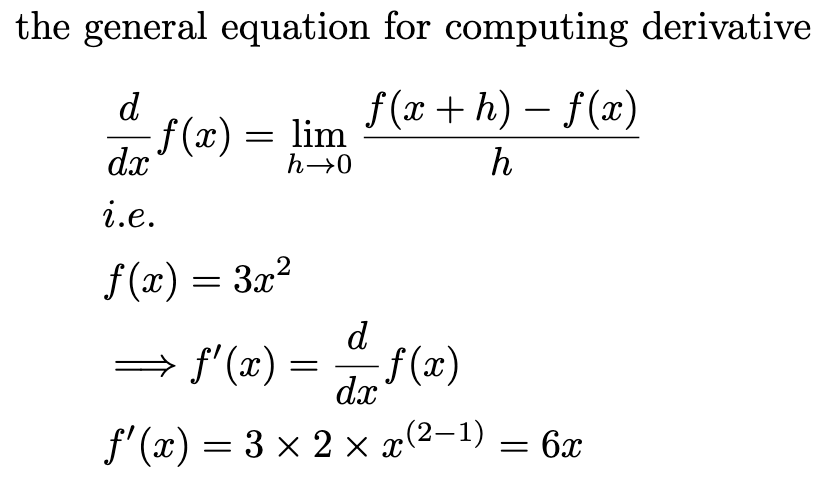
implementing the gradient above programmatically, pytorch requires inputs to a function be a Tensor with grad set to true, as seen in the initialization below, enabling the creation of a graph for tracking the operations and computing the gradients in the backward pass. This is the most fundamental concept in training neural networks, forward propagation and backward pass.\
Let's now understand better from a chain of operations, but before we continue further...
note that torch.Tensor returns a Torch.FloatTensor while torch.tensor infers the dtype automatically. It can also be noted that torch.Tensor does not have arguments like requires_grad, dtype, so torch.tensor is used in this case. In general, torch.tensor is recommended.
note that torch.Tensor returns a Torch.FloatTensor while torch.tensor infers the dtype automatically. It can also be noted that torch.Tensor does not have arguments like requires_grad, dtype, so torch.tensor is used in this case. In general, torch.tensor is recommended.
[Python]$ python3 playingWithGrads.py
a=tensor([0., 0., 0., 0.])
b=tensor(4)
d=tensor([0.0000, 0.2000, 0.4000, 0.6000, 0.8000])
e=tensor([0.0000, 0.2000, 0.4000, 0.6000, 0.8000], dtype=torch.float64)
g=tensor([1., 2., 4.])
h=tensor([1., 3., 5.], device='mps:0')
i=tensor([[3., 0.],
[4., 5.]])
j=tensor([[ 9., 0.],
[32., 25.]])
Also note, for requires_grad to not create an error, the data must be float data type. That is since for gradients to be defined, you need a continuous function, and float data is the way to represent continuity in such functions.
Note that the code below will give an error.
Note that the code below will give an error.
But when modified as below, it works okay.
back to our computational graph
Let's continue on, learning something interesting on compounded operations on computational graphs from the sum of gradients and on the product of gradients.
Essentially, the gradient of sums is the sum of gradients, hence for the computational graph as seen below, the gradient of a particular value in the leaf variable (to be explained what it means in a bit) does not depend on any other associated variable in the leaf variable.
Essentially, the gradient of sums is the sum of gradients, hence for the computational graph as seen below, the gradient of a particular value in the leaf variable (to be explained what it means in a bit) does not depend on any other associated variable in the leaf variable.
[Python]$ python3 playingWithGrads.py
tensor(450., grad_fn=<SumBackward0>)
tensor([ 6., 24., 54., 96., 150.])
Let's get into a bit more fun, understand mathematically and programmatically what happens when we change the torch.sum to torch.prod and derive the result
[Python]$ python3 playingWithGrads.py
tensor(55296000., grad_fn=<ProdBackward0>)
tensor([1.6589e+08, 8.2944e+07, 5.5296e+07, 4.1472e+07, 3.3178e+07])

[Python]$ python3 playingWithGrads.py
tensor(1.6589e+08)
tensor(82944000.)
tensor(55296000.)
tensor(41472000.)
tensor(33177600.)
tensor([1.6589e+08, 8.2944e+07, 5.5296e+07, 4.1472e+07, 3.3178e+07])
As can be seen, the computational graph is very essential and it is used in updating of weights in neural networks based on the gradients computed from the operations in the computational graph.
Let's understand one more of the computation graphs based on the chain rule of derivatives
Let's understand one more of the computation graphs based on the chain rule of derivatives
x values:
tensor([0.8823, 0.9150, 0.3829, 0.9593], requires_grad=True)
w values:
tensor([0.3904, 0.6009, 0.2566, 0.7936], requires_grad=True)
z:
tensor(3.0761, grad_fn=<PowBackward0>)
w grad values:
tensor([3.0948, 3.2096, 1.3430, 3.3650])

manual grad calculation:
tensor([3.0948, 3.2096, 1.3430, 3.3650])
torch grad calculation:
tensor([3.0948, 3.2096, 1.3430, 3.3650])
Dealing with computational graphs has been interesting. For more in-depth and thorough understanding of the computational graphs, that is the construction of the graphs in PyTorch and the execution of the graphs, look into these awesome articlescomputational graphs constructedandcomputational graphs execution
before we finish
Remember us talking about leaf Tensors. This is a variable that is at the beginning of a graph. These variables are the only variables that we can acquire the gradients using .grad. For instance, in the previous computations, we cannot access the gradients of y or of z because they do not start the graph.
x is leaf:
True
w is leaf:
True
y is leaf:
False
z is leaf:
False
Let us look into some variable initialization in Pytorch and see if they are characteristic of a leaf Tensor.
a is leaf True
a is leaf False
a is leaf False
a is leaf True
a is leaf True
a is leaf True
a is leaf False
With this look into passing input Tensor into a function to get the output foward pass, then doing a .backward() to compute the gradients of the leaf Tensor ( backpropagation ) is the very core of optimization, which we'll have fun exploring in future sections.