66 years too soon
The year is July 1958, the unveiling is by the Office of Naval Research, the creator, Frank Rosenblatt, the invention, perceptron. So what is it?
“the first machine capable of having an original idea” ~ Frank Rosenblatt
This invention was first inspired by the working of neurons in the brain, and so it was of concern to build a machine that could classify a given input into two categories, let's say a cat or a dog - and if wrong, would then tweak itself to make a more informed prediction the next time.
Rosenblatt wrote ~ “Yet we are about to witness the birth of such a machine – a machine capable of perceiving, recognizing and identifying its surroundings without any human training or control.”
Marvin Minsky, a fellow, however commented that the functions were just too simple hence perceptron could never achieve its goal.
And I quote this article from Cornell
Professor’s perceptron paved the way for AI – 60 years too soon
The problem was, Rosenblatt’s perceptron had only one layer, while modern neural networks have millions.
“What Rosenblatt wanted was to show the machine objects and have it recognize those objects. And 60 years later, that’s what we’re finally able to do,” Joachims said. “So he was heading on the right track, he just needed to do it a million times over. At the time, he didn’t know how to train networks with multiple layers. But in hindsight, his algorithm is still fundamental to how we’re training deep networks today.”
Onto the classical model of a perceptron, the first ever linear classifier
Mark Hasegawa-Johnson, CS 440, Spring 2018
“the first machine capable of having an original idea” ~ Frank Rosenblatt
This invention was first inspired by the working of neurons in the brain, and so it was of concern to build a machine that could classify a given input into two categories, let's say a cat or a dog - and if wrong, would then tweak itself to make a more informed prediction the next time.
Rosenblatt wrote ~ “Yet we are about to witness the birth of such a machine – a machine capable of perceiving, recognizing and identifying its surroundings without any human training or control.”
Marvin Minsky, a fellow, however commented that the functions were just too simple hence perceptron could never achieve its goal.
And I quote this article from Cornell
Professor’s perceptron paved the way for AI – 60 years too soon
The problem was, Rosenblatt’s perceptron had only one layer, while modern neural networks have millions.
“What Rosenblatt wanted was to show the machine objects and have it recognize those objects. And 60 years later, that’s what we’re finally able to do,” Joachims said. “So he was heading on the right track, he just needed to do it a million times over. At the time, he didn’t know how to train networks with multiple layers. But in hindsight, his algorithm is still fundamental to how we’re training deep networks today.”
Onto the classical model of a perceptron, the first ever linear classifier
Mark Hasegawa-Johnson, CS 440, Spring 2018
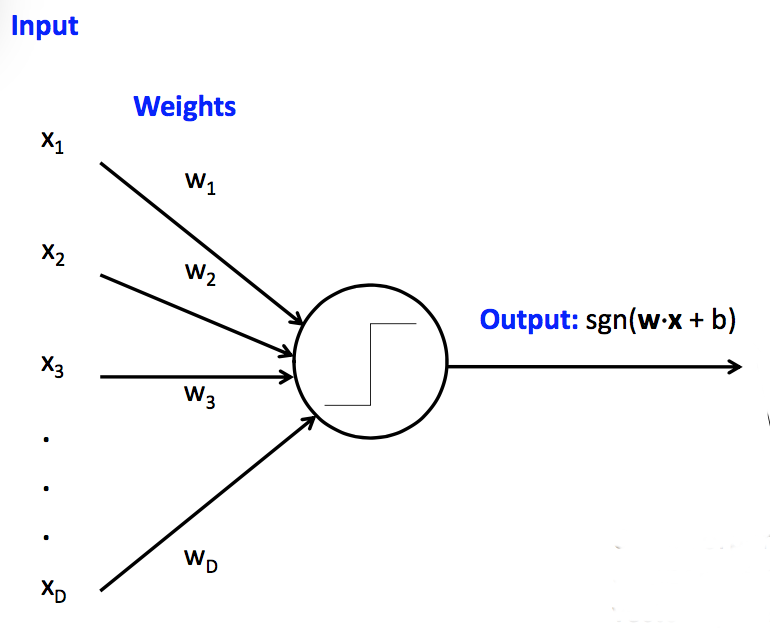
What essentially happens in a perceptron? There's inputs, a vector x, and the weights, a vector, w, and a scalar value, a bias. The operations are a dot product of x and w to get an output which is then added to the bias. This is then passed to the signum function to obtain the final output of the perceptron.
Note: The first perceptron ever implemented was a machine, rather than a program. It was implemented in a custom built hardware, "Mark-1 perceptron", and was purely an analog computer with knobs to adjust the weights and weight updates during learning performed by electric motors.
Originally, the perceptron used a step function. For the one in the figure, a signum function is used.
Let's implement it using Pytorch.
Note: The first perceptron ever implemented was a machine, rather than a program. It was implemented in a custom built hardware, "Mark-1 perceptron", and was purely an analog computer with knobs to adjust the weights and weight updates during learning performed by electric motors.
Originally, the perceptron used a step function. For the one in the figure, a signum function is used.
Let's implement it using Pytorch.
torch.Size([2])
tensor([-1.])
An input will be passed to the perceptron, to compute dot product and pass through the activation function sgn to get output yhat, in the forward pass. This will be used together with actual value y in the loss function, in our case a simple y-yhat, which will then guide the adjustments for the weights during the perceptron learning rule, discussed next.
This, for a general complex neural network, is going back the computational graph computing the gradients till the leaf Tensors then using the .grad values of each node in the network to compute the new weights in the network in hopes of convergence to the minimum in the backward pass. Then repeating again!
Now onto the perceptron learning rule, in the modern day it is known as updating the weights using optimizers such as Stochastic Gradient Descent or Adam in the backward pass.
This, for a general complex neural network, is going back the computational graph computing the gradients till the leaf Tensors then using the .grad values of each node in the network to compute the new weights in the network in hopes of convergence to the minimum in the backward pass. Then repeating again!
Now onto the perceptron learning rule, in the modern day it is known as updating the weights using optimizers such as Stochastic Gradient Descent or Adam in the backward pass.

Now, let's make a small change to our class above, add method called predict for predicting new values once we have trained our perceptron model, and plot, for visualizing the average accuracy for each epoch all the way to the last epoch, no early stopping mechanism implemented.
linearly separable data
Now that we have implemented our perceptron, let us create data to train it on. Since perceptron is a linear classifier, it can only learn linearly separable functions, that is, the two sets in the data due to mapping by the function can be separated by at least one line in the plane. The code below does generate the data for us. Because it is not the focus of the course, I will not explain it, also it is not hard to understand.
On visualizing the dataset, except for a single sample which we can consider an outlier, we can draw a single line to distinguish the two classes
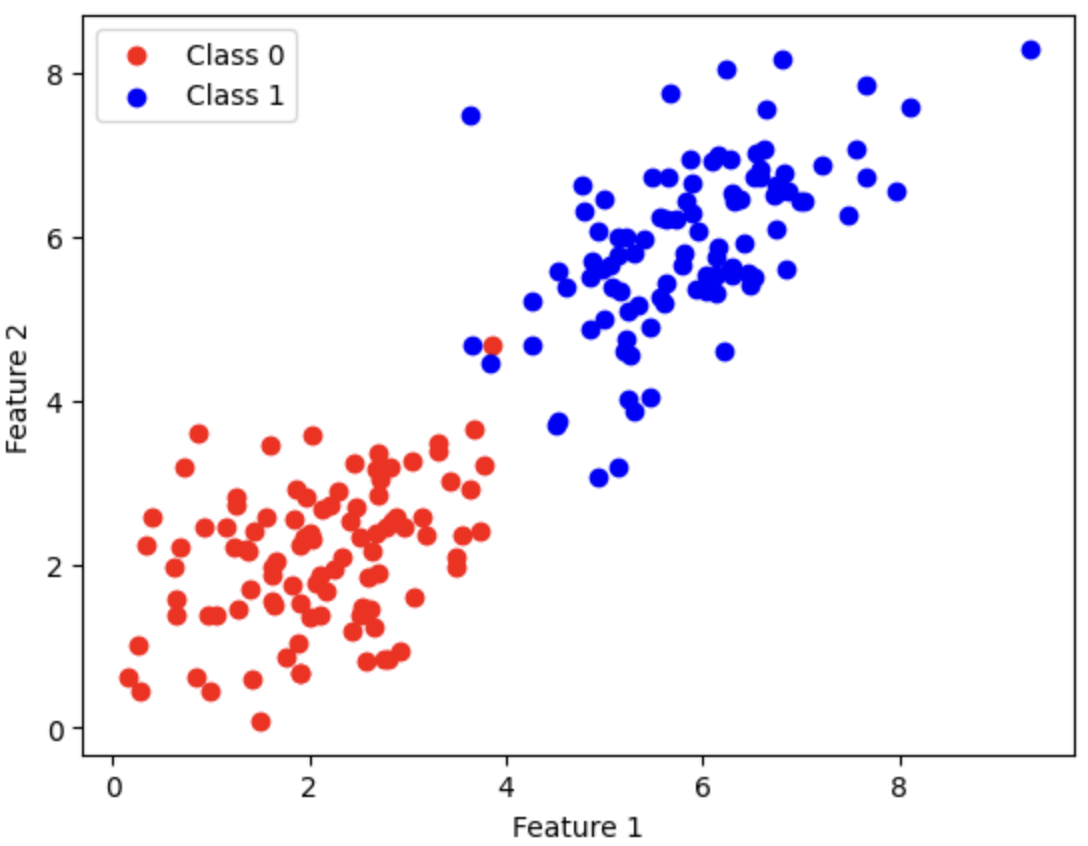
Nice! Now, let's see the performance of our perceptron right before we train it to see how badly it is with the randomly initialized weights.
Accuracy is at 50%, meaning it performs as good as a fair coin toss experiment. Now let's train the perceptron.
accuracy: 0.48
accuracy: 0.52
accuracy: 0.74
accuracy: 0.90
accuracy: 0.89
accuracy: 0.95
accuracy: 0.95
accuracy: 0.96
accuracy: 0.96
accuracy: 0.93
accuracy: 0.97
accuracy: 0.97
accuracy: 0.96
accuracy: 0.96
accuracy: 0.93
accuracy: 0.97
accuracy: 0.97
accuracy: 0.95
accuracy: 0.96
accuracy: 0.97
accuracy: 0.96
accuracy: 0.96
accuracy: 0.96
accuracy: 0.95
accuracy: 0.99
accuracy: 0.96
accuracy: 0.96
accuracy: 0.95
accuracy: 0.96
accuracy: 0.96
accuracy: 0.96
accuracy: 0.99
accuracy: 0.99
accuracy: 0.97
accuracy: 0.96
accuracy: 0.99
accuracy: 0.99
accuracy: 0.96
accuracy: 0.99
accuracy: 0.97
accuracy: 0.96
accuracy: 0.96
accuracy: 0.98
accuracy: 0.97
accuracy: 0.98
accuracy: 0.99
accuracy: 0.99
accuracy: 0.99
accuracy: 0.97
accuracy: 0.98
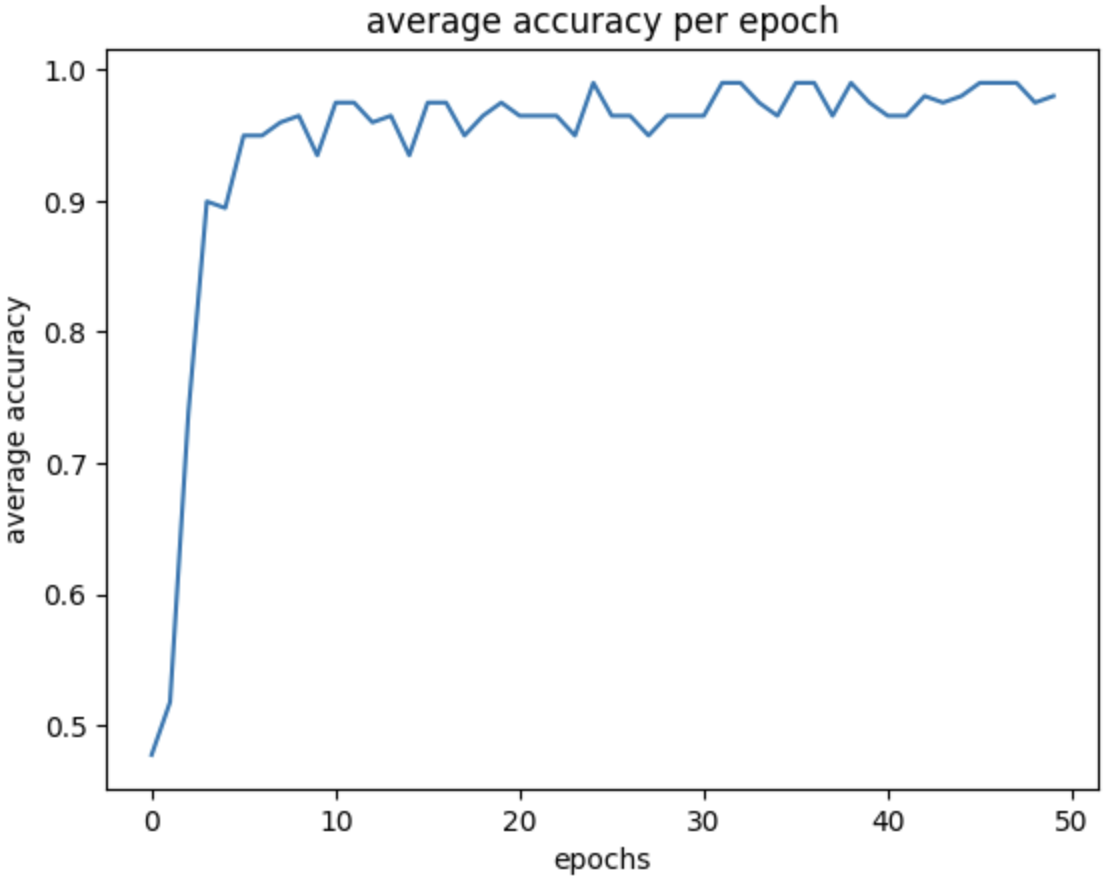
Now on running this again
accuracy: 0.98
And that would be a wrap for awesome learning of perceptron algorithm.